ML Lecture 6 Artificial Neural Network
人工神经网络结构
一个神经网络包含以下四个组成:
- 输入层(Input layer)
- 一个或多个隐藏层(Hidden layers)
- 输出层(Output layer)
- 各层之间的连接(Connections)
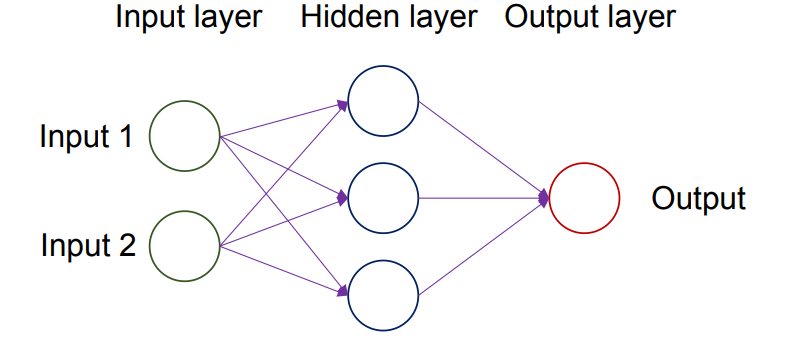
在网络中,信号在神经元之间被处理并传递:上一层神经元的输出作为下一层神经元的输入,通过连接权重加权后再送入激活函数。
激活函数 Activation functions
激活函数用于在神经元中引入非线性,常见的有:
Sigmoid 函数,记作
sigm双曲正切函数(tanh),记作
tanh修正线性单元(Rectified Linear Unit, ReLU),记作
ReLU
神经元内部的计算与激活 Processes and activation within a neuron
一个神经元通常包含:
- 权重向量
- 偏置项
- 激活函数(如 sigmoid、tanh、ReLU 等)
其基本计算步骤包括:
- 乘法(Multiplication):输入与权重相乘
- 加法(Addition):乘积求和并加上偏置
- 激活(Activation):对线性结果应用激活函数
假设输入为
第一层神经元:
- 权重:
- 偏置:
- 线性部分:
- 激活输出(采用 sigmoid):
记该输出为新的输入
- 权重:
下一层神经元:
- 权重:
- 偏置:
- 线性部分:
- 激活输出(同样使用 sigmoid):
- 权重:
通过这样的“乘法 → 加法 → 激活”过程,信号在网络中一层层传播并被非线性变换。

在神经网络中引入激活函数(Activation Function)来增加非线性,其核心意义可以总结为一句话:赋予神经网络处理复杂问题的能力(即提高模型的表达能力)。
如果没有非线性激活函数,且各层只做仿射变换,无论神经网络有多少层,它整体上都等价于一个单层线性/仿射模型。
如果不用激活函数: 神经网络的每一层都在做线性变换(
)。线性函数的线性组合仍然是线性函数。 假设你有一个两层的网络: 1. 第一层输出: 2. 第二层输出: 代入后你会发现:
$$y = w_2(w_1 x + b_1) + b_2 = (w_2 w_1)x + (w_2 b_1 + b_2) = W'x + B'$$
这说明,没有非线性激活函数,多层网络在数学上等价于单层网络。你费劲搭建的“深度”网络会塌缩成一个简单的线性模型,无法学习复杂的特征。
- 引入激活函数后: 每一层的输出经过非线性变换(如 ReLU, Sigmoid),打破了线性的叠加。使得足够宽或足够深的神经网络能够逼近范围很广的非线性函数。
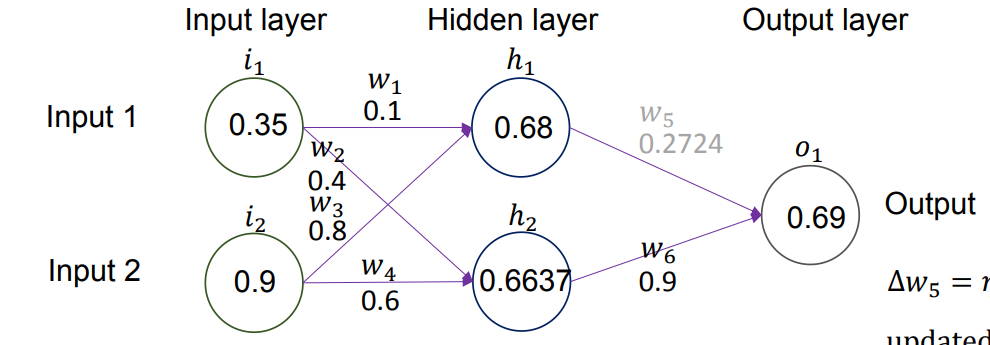
向前传播 Forward Propagation
向前传播就是把输入数据从输入层依次传到输出层、并在每一层完成“加权求和 + 加偏置 + 过激活函数”的计算过程:对某一层的每个神经元,先把上一层各神经元的输出乘以对应权重后相加,再加上一个偏置项得到
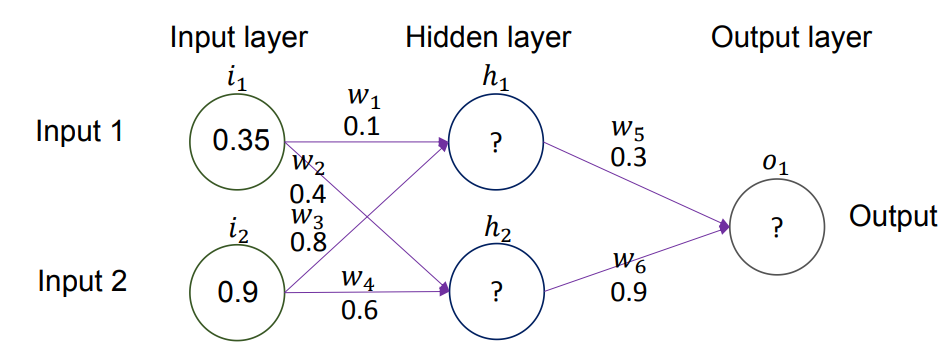
- 输入向量 Input:
[0.35, 0.9] - 期望输出 Expected output:
[0.5] - 激活函数 Activation function: Sigmoid 函数 Sigmoid function
注意:激活函数 Activation function 不作用于 输入层 Input layer。
- 第一步:计算隐藏层神经元
加权求和(Weighted Sum,
): 我们将输入值乘以对应的权重,然后相加。 - 输入
乘以权重 。 - 输入
乘以权重 。 - 计算:
- 输入
激活处理(Activation,
): 将求和结果 代入 Sigmoid 函数。 - 计算:
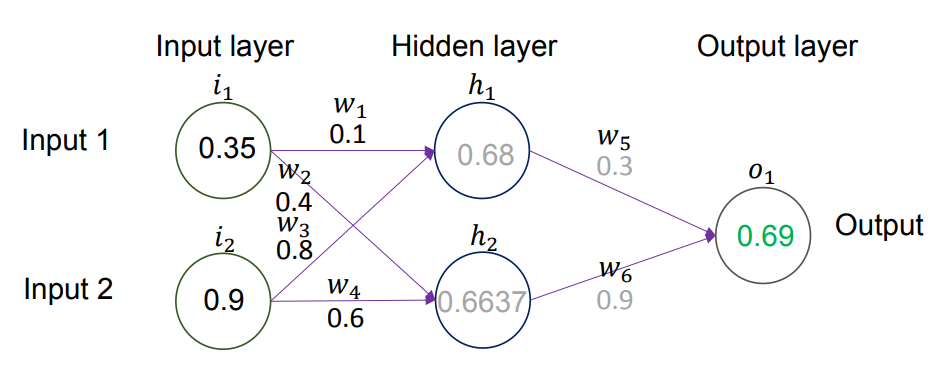
- 结果:隐藏层第一个神经元
的输出值为 0.68。
- 计算:
- 第二步:计算隐藏层神经元
加权求和(Weighted Sum,
): 同样地,计算连接到 的输入加权和。 - 输入
乘以权重 。 - 输入
乘以权重 。 - 计算:
- 输入
激活处理(Activation,
): 将求和结果 代入 Sigmoid 函数。 - 计算:
- 结果:隐藏层第二个神经元
的输出值为 0.6637。
- 计算:
- 第三步:计算输出层神经元
加权求和(Weighted Sum,
): - 隐藏层输出
乘以权重 。 - 隐藏层输出
乘以权重 。 - 计算:
- 隐藏层输出
激活处理(Activation,
): 将求和结果 代入 Sigmoid 函数。 - 计算:
- 计算:
向后传播 Backward Propagation
向后传播(Backpropagation)是神经网络训练的核心算法,本质上是一种基于微积分链式法则的高效梯度计算机制。在神经网络完成前向传播并计算出预测值与真实标签之间的误差(Loss)后,向后传播会将这个误差从输出层反向传递回输入层。在这个过程中,算法逐层计算损失函数相对于网络中每一个权重和偏置的偏导数(即梯度),从而精确量化每个参数对最终总误差的“贡献程度”。形象地说,它就像是一个自动化的“归责系统”,通过反向推导找出导致预测偏差的具体原因,明确告诉网络中的每一个参数:为了让结果更准确,你应该变大一点还是变小一点,以及变化的幅度需要多大。
向后传播的目的和作用在于指导神经网络进行参数优化,从而实现模型的“学习”。它为梯度下降等优化算法提供了至关重要的导航信息——梯度。如果没有向后传播,优化器就无法知道参数更新的正确方向,网络也就无法从错误中吸取教训。通过向后传播计算出的梯度,优化算法能够有的放矢地微调成千上万个权重参数,使得模型在下一次前向传播时的预测误差减小。随着“前向预测—反向求导—参数更新”这一循环的反复进行,神经网络的性能逐渐收敛,最终具备处理复杂任务的预测能力。
损失函数 Loss function
单个神经元示例 Single neuron example
- 权重 Weight:
- 偏置 Bias:
- 输入到神经元的值 Input to the neuron:
- 神经元输出 Output:
若 真实值 Ground truth(即期望输出 expected value)设为
则要回答:
这就需要用 损失函数 Loss function 来量化预测效果。
设共有
平均绝对误差 Mean absolute error(MAE)
本例只有一个样本:
平均平方误差 Mean squared error(MSE)
(课件后面使用的是带的形式,便于求导) 本例:
均方根误差 Root mean squared error(RMSE)
本例:
梯度下降算法 Gradient descent algorithm
- (最快)下降方向是 梯度 Gradient 的相反方向。
- 按小步迭代,逐步逼近最小值。
- 步长由 学习率 Learning rate 控制。
最简单情形下的更新公式:
即:
- 先计算损失对权重的偏导数 梯度 Gradient;
- 再沿负梯度方向更新权重,使损失减小。
逐项计算:
误差对输出的导数:
输出对加权和
的导数(Sigmoid 的导数): 加权和对权重
的导数:
于是:
权重更新(梯度下降):
对
这里:
最终可以得到新的
反向传播:更新隐藏层权重 Updating hidden-layer weights
现在考虑隐藏层上的权重,例如
同样问题:
根据 链式法则 Chain rule:
通常把
称为输出层的 误差项 Delta,记作
各项分别为:
因此可以简化为:
代入数值(课件给出的数值):
同理,可以得到
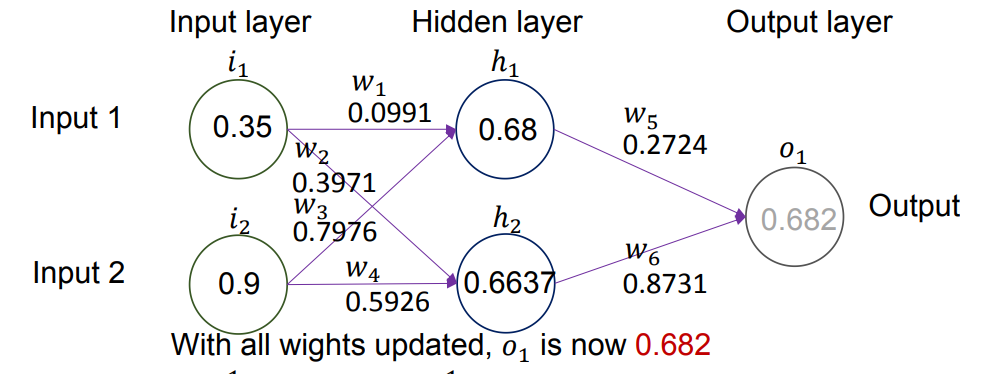
一次前向 + 反向传播之后 Forward and backward propagation
一次完整的前向 + 反向更新后,各权重大致变为:
用这些新权重重新进行一次 前向传播 Forward propagation,得到新的输出:
新的误差为:
相比之前的
实际训练中需要进行多次迭代 More iterations 才能得到更好的结果。
预测阶段 Prediction phase
当通过多次训练后,假设权重已经收敛到某个较优解,例如:
此时对同样的输入 [0.35, 0.9] 做 前向传播 Forward propagation,可以得到:
- 隐藏层输出大致为:
- 输出层结果:
因此,网络输出
这就是训练好的网络在 预测阶段 Prediction phase 的工作方式:
给定输入,通过前向传播直接给出输出,不再进行反向传播和权重更新。
神经网络训练
训练轮次与批量训练 Training epochs and batch training
使用一个训练样本进行一次参数更新:
- 包含
次 前向传播 Forward propagation - 和
次 反向传播 Backward propagation
- 包含
一个 轮次 Epoch 的含义:
- 完整遍历训练集一次
- 在 SGD 中通常近似为:样本数 number of training samples
(前向 + 反向传播);在 batch/mini-batch 训练中则按批次更新。
批量训练 Batch training:
- 基于平均损失 averaged loss 来更新模型参数
- 有时会使用 小批量 Mini-batch 的方式
小批量梯度下降 Mini-batch Gradient Descent(MBGD)
在 批量梯度下降 Batch Gradient Descent, BGD 中,每次用所有样本 all samples 来更新参数。
在 随机梯度下降 Stochastic Gradient Descent, SGD 中,每次只用一个样本 a single sample。
在 小批量梯度下降 Mini-batch Gradient Descent, MBGD 中,每次使用一个小批量 mini-batch。
一个 小批量 mini-batch 是包含
个训练样本的子集,满足 为总样本数)。 被称为 批大小 Batch size。
MBGD 的基本流程
- 将数据集划分为多个 小批量 mini-batches。
- 从训练集中取出一个 小批量 mini-batch。
- 计算该小批量上损失函数的平均梯度 Mean gradient。
- 根据这个平均梯度更新模型参数。
- 对所有小批量重复步骤 2)–4)。
MBGD 的超参数与性质 Hyperparameter and properties
在 MBGD 中,
- 较小的
Small :行为更接近 SGD。 - 较大的
Large :行为更接近 BGD。
通常一个比较常见的默认值是
MBGD 结合了 BGD 和 SGD 的优点,因此:
- 在一定程度上可以避免收敛到局部极小值 Local minima。
- 需要的内存 Memory 较少。
- 收敛速度 Convergence speed 较快。
Adam 优化器 The Adam optimizer
普通梯度下降 Gradient descent
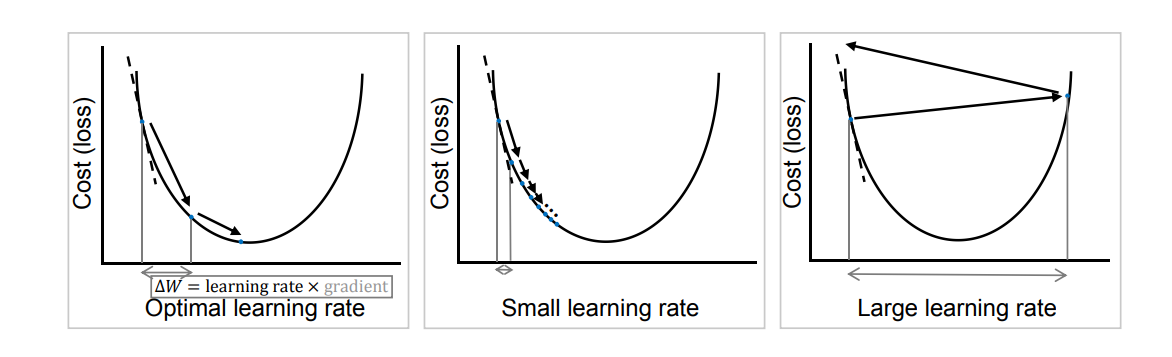
- 使用固定学习率 Fixed learning rate,对所有参数都相同。
- 学习率过小,会导致收敛太慢;
- 学习率过大,可能震荡甚至发散。
Adam 优化器 Adam optimizer
- Adam 是一种具有自适应学习率 Adaptive learning rate 的优化算法。
- 对不同参数使用不同的、随时间变化的学习率。
- 它利用梯度的一阶矩和二阶矩的估计:
- 一阶矩 First moment:类似于梯度的均值 Mean。
- 二阶矩 Second moment:类似于梯度平方的均值 Mean of squared gradients。
主要优点:在实践中通常效率高 Efficient、收敛速度快,调参相对简单。
总结
要得到一个可用的 神经网络模型 Neural network model,通常需要以下几个步骤:
给定初始权重和偏置 Initialize weights and bias
- 一种常用方法是随机初始化 Random initialization。
根据输入计算输出 Compute output from inputs
- 这一步就是 前向传播 Forward propagation。
- 输入数据来自训练集 Training data。
根据输出与标签的差异定义损失函数 Define loss function
- 计算网络输出与真实标签之间的差异。
- 常见损失函数包括:
损失 L1 loss - 均方误差损失 MSE loss
- 交叉熵损失 Cross-entropy loss 等。
计算损失函数的梯度 Compute gradients of the loss function
- 反向传播 Back propagation 负责高效计算梯度;随后由优化器利用这些梯度更新参数、最小化损失。
- 可选的优化方法很多,例如:
- 随机梯度下降 Stochastic Gradient Descent, SGD
- Adadelta
- 自适应矩估计 Adaptive Moment Estimation, Adam 等。
当损失足够小 When the loss is small enough
- 保存当前的 权重 Weights 和 偏置 Bias,作为最终的网络模型。
神经网络训练的高级主题 Advanced topics in neural network training
挑战 Challenges
梯度消失 Vanishing gradients
- 在远离输出层的深层网络中,梯度非常小。
- 结果:学习速度变慢 Learning slows down。
梯度爆炸 Exploding gradients
- 网络中的梯度非常大。
- 结果:训练不稳定 Instability in learning。
解决
- 权重初始化 Weight initialization
- 梯度裁剪 Gradient clipping
- 激活函数 Activation function
- 批归一化 Batch normalization
- 跳跃连接 Skip connection
- 学习率 Learning rate
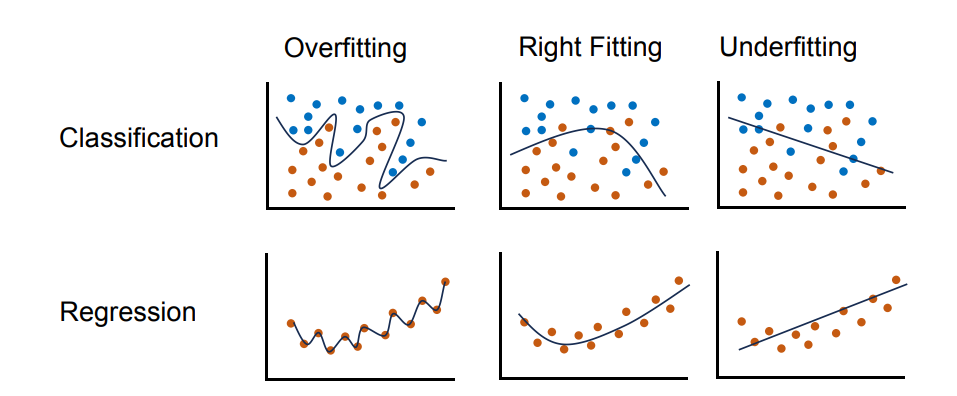
欠拟合与过拟合 Underfitting and overfitting
三种拟合情况 Three fitting regimes
过拟合 Overfitting
- 在图中,模型在训练集上的决策边界/曲线非常弯曲,过分关注训练数据中的细微模式。
- 定义:模型过于关注训练集中的细节和噪声,Overfitting: the model pays attention to subtle patterns in the training set。
恰当拟合 Good fitting / Right fitting
- 模型既能很好地拟合训练数据,又能对未见数据有良好的泛化能力。
欠拟合 Underfitting
- 在图中,模型曲线过于简单,无法捕捉真实关系。
- 定义:模型未能学习到训练集中潜在的真实关系,
Underfitting: the model fails to capture the underlying relationships in the training set。
训练集与测试集上的损失 Loss on training and test sets
| 情况 Case | 训练集 Training set | 测试集 Test set |
|---|---|---|
| 过拟合 Overfitting | 低损失 Low loss | 高损失 High loss |
| 恰当拟合 Good fitting | 低损失 Low loss | 低损失 Low loss |
| 欠拟合 Underfitting | 高损失 High loss | 高损失 High loss |
欠拟合:原因与解决方案 Underfitting, reasons and solutions
欠拟合的原因及对应解决方案 Causes of underfitting and solutions:
训练数据多样性不足 Limited training data diversity
- 解决:数据采集 Data acquisition,收集更多能代表整体分布的数据。
特征稀缺或不相关 Feature scarcity and irrelevance
- 解决:数据预处理 Data preprocessing 与 特征选择 Feature selection,构造和筛选更有信息量的特征。
超参数设置不当 Inappropriate hyperparameter setting
- 解决:微调模型的 超参数 Hyperparameters,包括
学习率 Learning rate、激活函数 Activation function、批大小 Batch size 等。
- 解决:微调模型的 超参数 Hyperparameters,包括
训练轮次不足 Lack of training iterations
- 解决:增加训练时间和训练轮次,直到模型收敛。
模型复杂度不足 Insufficient model complexity
- 解决:为神经网络添加更多的 层 layers 和/或 神经元 neurons。
过拟合:原因与解决方案 Overfitting, reasons and solutions
过拟合的原因及对应解决方案 Causes of overfitting and solutions:
训练样本不足 Insufficient training samples
- 解决:通过数据采集 Data acquisition 获取更多样本。
数据不平衡 Imbalanced data
- 解决:在不平衡数据上使用加权决策等方法,
Applying weighted decision-making on imbalanced data。
- 解决:在不平衡数据上使用加权决策等方法,
数据泄漏 Data leakage
- 解决:严格保证 测试集样本 test set samples 不参与训练过程。
超参数设置不当 Inappropriate hyperparameter settings
- 解决:微调模型 超参数 Hyperparameters,包括
学习率 Learning rate、激活函数 Activation function、批大小 Batch size 等。
- 解决:微调模型 超参数 Hyperparameters,包括
缺乏正则化 Lack of regularization
- 解决:在训练中加入 正则化 Regularization,例如
正则化、Dropout 等。
- 解决:在训练中加入 正则化 Regularization,例如
模型过于复杂 Excessive model complexity
- 解决:适当减少网络的 层数 layers 和/或 神经元数量 number of neurons,简化模型结构。
缓解过拟合的一些方法 A few methods to improve overfitting
下面介绍几种常见的缓解 过拟合 Overfitting 的技术:
- 正则化 Regularization
- 训练集/验证集/测试集划分 Training-validation-test splitting
- 早停 Early stopping 等。
正则化 Regularization
在原有损失函数的基础上加入加权的 正则项 Regularization term
:误差函数 Error function,刻画预测和真实标签的差异 :正则化系数 Regularization coefficient,控制数据误差与正则项之间的权衡 :与函数 的复杂度相关的惩罚项 复杂度惩罚 penalty on the complexity of
如果没有正则项 Without regularization term,损失函数为:
此时模型可能会变得非常复杂,几乎“记住 memorize” 所有训练样本
加入
- 惩罚过于复杂的模型
- 鼓励较平滑、复杂度较低的函数
- 使模型在新样本 New data samples 上具有更好的泛化能力 Generalization ability
图示对比了未正则化模型(曲线剧烈波动)和正则化后的模型(更平滑)。
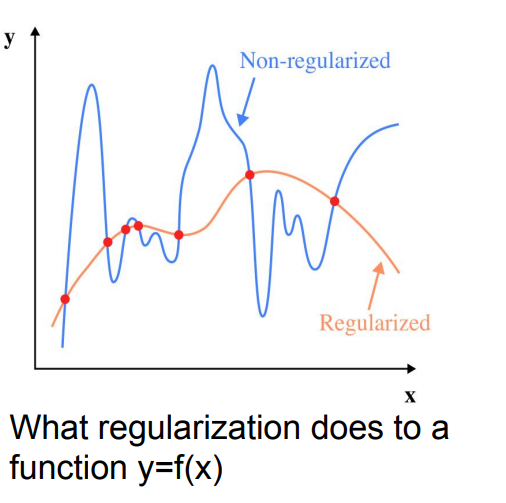
L1 正则化 L1 Regularization
L1 正则化 L1 regularization,也称为 Lasso 回归 Lasso regression:
正则项形式:
其中
为模型参数系数 model parameter coefficients。
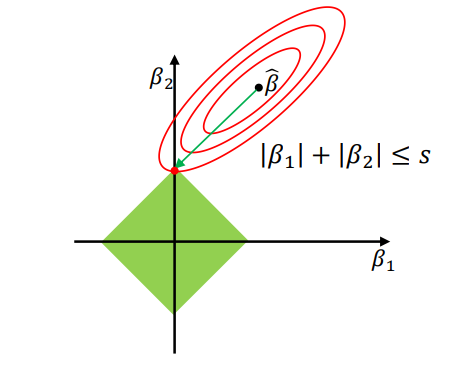
目标是最小化带惩罚的损失函数:
图中红色等高线表示原始损失函数的优化景观 Optimization landscape,绿色菱形是 L1 约束
交点
(带帽的 )为给定训练集下损失最小的参数: :最优参数估计值 Parameter coefficients with minimum loss
L1 正则化的一个重要效果:
- 会把一些不重要的参数 Less important coefficients(例如图中的
)压缩到 , - 从而实现特征选择 Feature selection 和稀疏模型。
- 会把一些不重要的参数 Less important coefficients(例如图中的
L2 正则化 L2 Regularization
同样,
L2 正则化 L2 regularization,也称为 岭回归 Ridge regression:
正则项形式:
其中
仍为模型参数系数 model parameter coefficients。
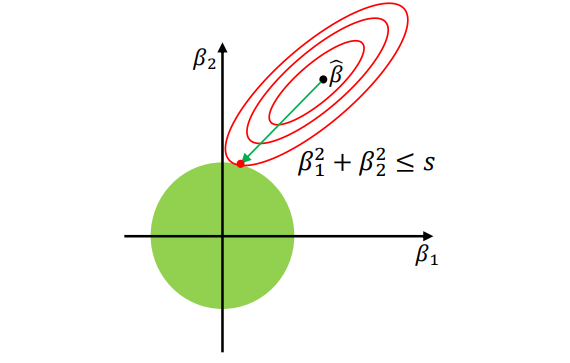
图中绿色圆形表示 L2 约束区域:
L2 正则化的效果:
- 将参数向量
均匀地向原点拉回 Draws back toward origin evenly - 不会像 L1 那样把参数变为严格的
,但会整体减小参数大小 - 通常能得到较少过拟合 less overfit 的模型
- 将参数向量
训练集–验证集–测试集划分 Training-validation-test splitting
在训练过程中需要评估模型 Evaluate the model while training。
常见做法是把完整数据集划分为三个集合:
训练集 Training set
- 用来训练模型参数。
验证集 Validation set
- 在训练过程中定期评估模型性能。
- 用于选择超参数、判断是否停止训练等。
测试集 Test set
- 在训练和调参结束后,作为最终评估 Final testing 使用。
- 不参与训练和模型选择。
基本流程:
- 首先从完整数据集 Full dataset 随机采样,进行 训练集–测试集划分 Training-test splitting。
- 在训练部分内部,再随机划分出 验证集 Validation set。
- 一般依据验证集的误差曲线来决定是否停止训练:
- 当验证误差不再下降或开始上升时,停止训练。
- 这就是 早停 Early stopping 的思想。
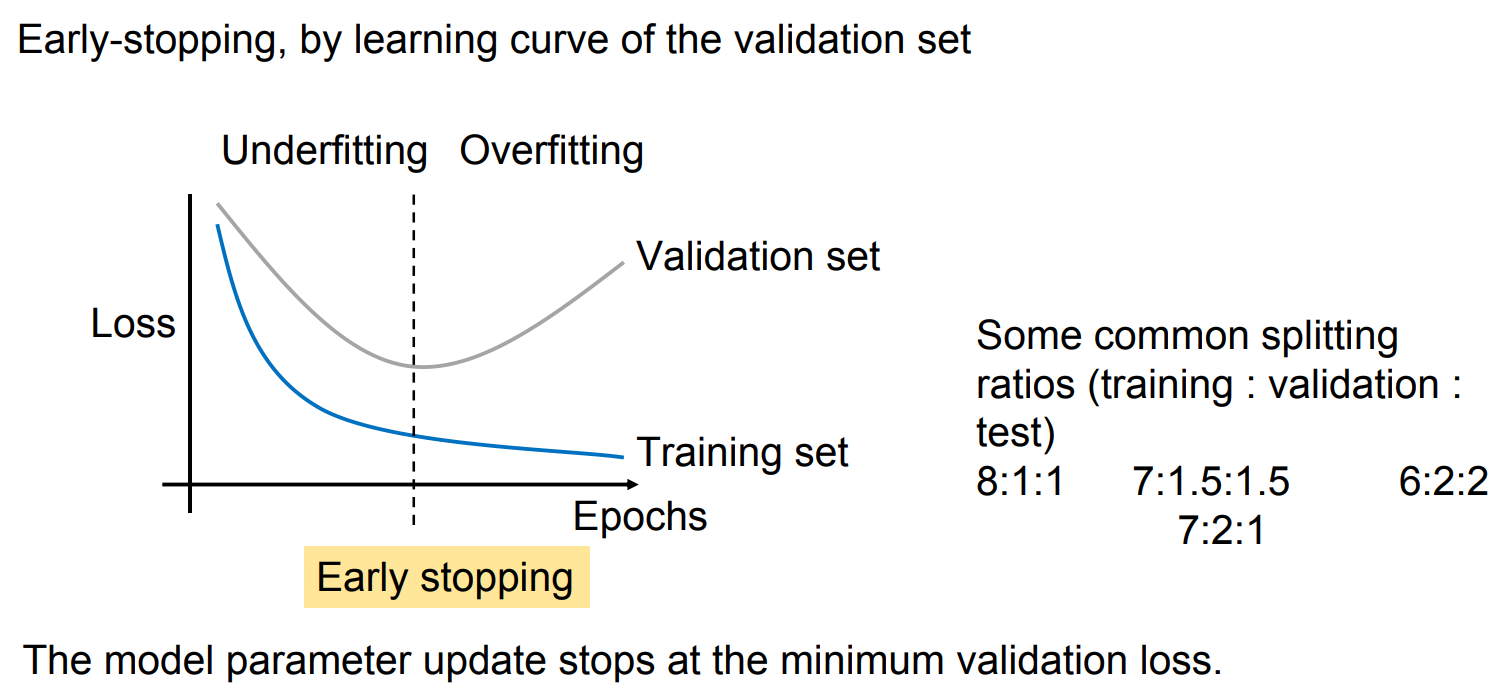
过拟合与训练曲线 Overfitting – training curve
通过观察 验证集 Validation set 的学习曲线,可以进行早停:
- 横轴:训练轮次 Epochs
- 纵轴:损失 Loss
随训练进行:
- 训练集损失 Training set loss 通常持续下降。
- 验证集损失 Validation set loss 先下降、后上升:
- 前期:模型尚未充分学习,属于 欠拟合 Underfitting 区域。
- 中间:验证集损失达到最低点,模型处于最佳拟合 Good fitting。
- 后期:验证集损失开始上升,说明出现 过拟合 Overfitting。
早停 Early stopping:
- 当验证集损失在若干轮内不再改善时停止更新模型参数,并通常恢复到验证集表现最好的那一轮。
- 即:Stop when validation loss no longer improves, and keep the best validation checkpoint。
常见的训练集 : 验证集 : 测试集划分比例示例:
这些比例可以根据数据规模和任务需求灵活调整。